
따릉이
[머신러닝] Kmean 클러스터링 본문
1. Steps
- 데이터를 준비한다.
- 얼만큼의 클러스터가 필요한지 결정한다.
- 클러스터의 중심 (centroid) 설정한다.
- 모든 데이터를 가장 인접한 클러스터에 지정한다.
- centroid를 클러스터에 속한 데이터들의 중심으로 이동시킨다.
- step 4, 5를 반복한다. -> 클러스터의 변화가 일어나지 않을 때 까지
2. Example
1. 데이터 준비

2. 3개의 클러스터 지정

3. 모든 데이터들을 인접 클러스터에 지정
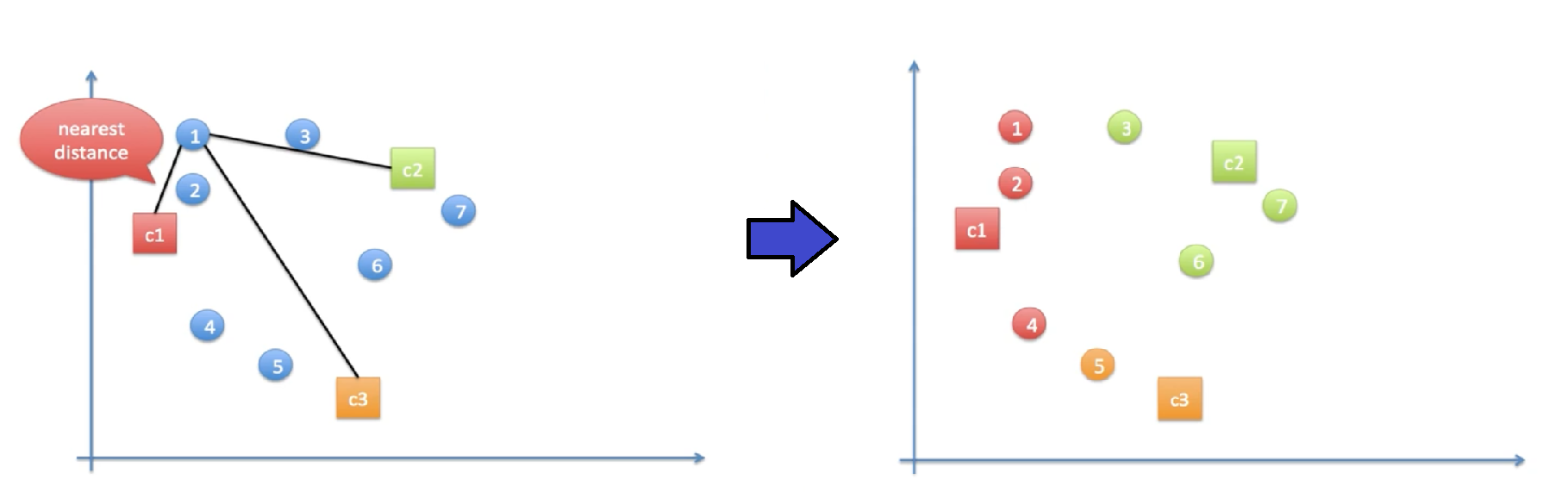
4. centroid를 클러스터에 속한 데이터들의 중심으로 이동

5. 3, 4의 과정을 반복
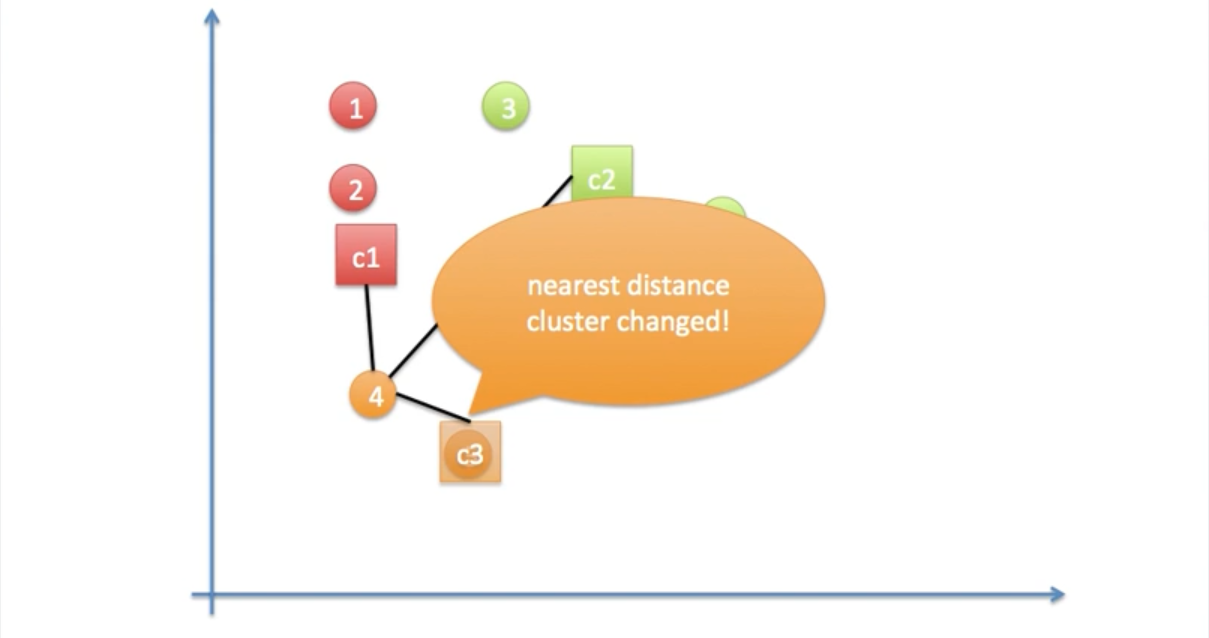

3. Centroid를 초기화하는 방법
- randomly choose ( 위의 방법 )
- manually assign init centroid : 수동으로 지정
- k-mean++ : 1번째 data point를 첫번째 centroid로 지정 후, 가장 멀리있는 data들을 다음 centroid로 지정


4. 실습




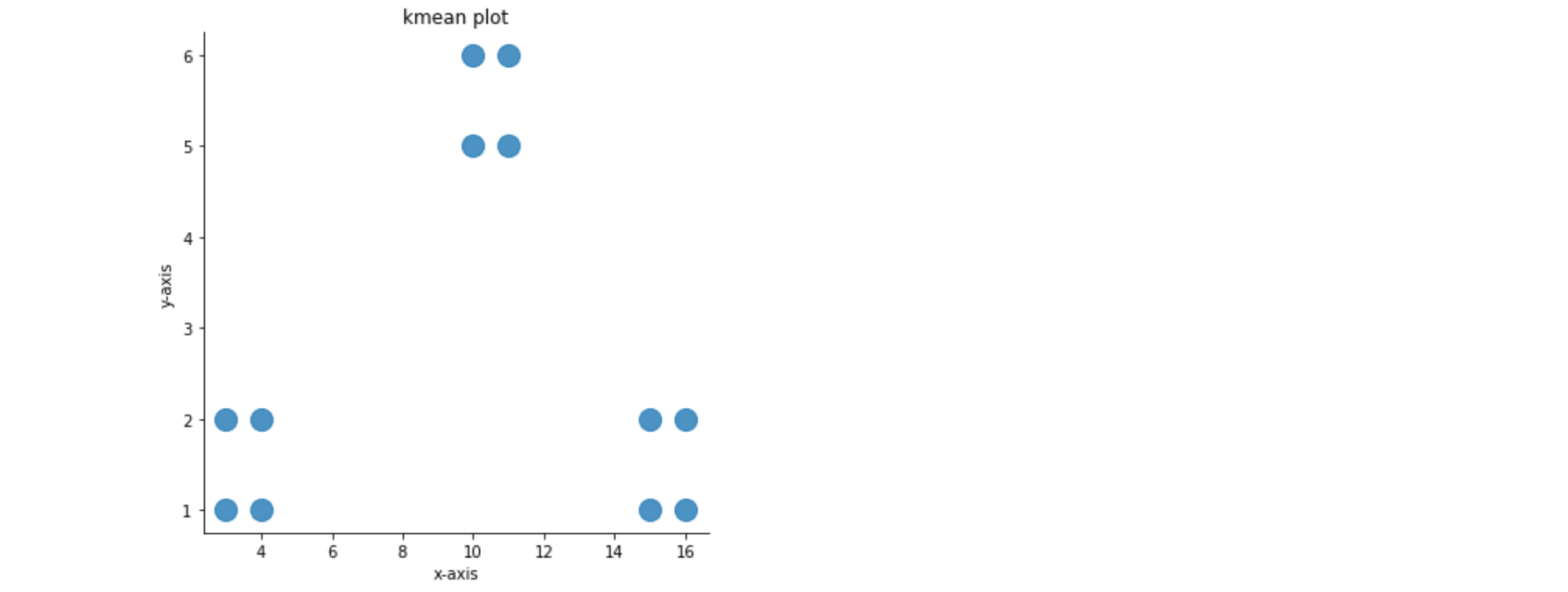



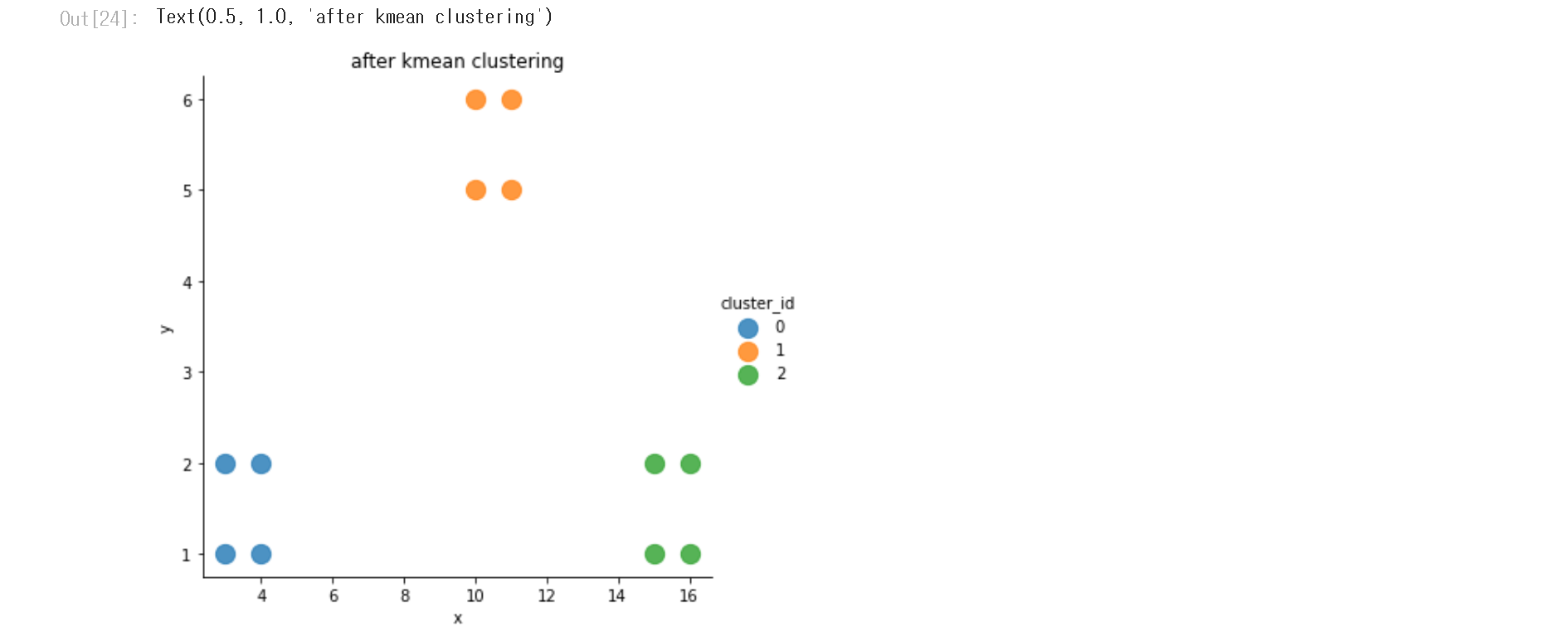
머신러닝 이론 및 파이썬 실습 - 인프런
머신러닝 총정리 강의입니다. 실무 경험을 토대로하여 짧고 알기쉬운 동영상 강의로 이루어져있습니다. 초급 인공지능 데이터 사이언스 프로그래밍 언어 Python 머신러닝 온라인 강의 머신러닝
www.inflearn.com
'머신러닝' 카테고리의 다른 글
| [머신러닝] 다중선형회귀(Multiple Linear Regression) (0) | 2021.01.17 |
|---|---|
| [머신러닝] 머신러닝의 학습 방법 (0) | 2021.01.17 |
| [머신러닝] 하루 노동 시간이 8시간 일 때의 하루 매출을 예측 (0) | 2021.01.14 |
| [머신러닝] k-mean 클러스터링(군집화) (0) | 2021.01.12 |
| [머신러닝] 머신러닝의 종류 (0) | 2021.01.10 |
'머신러닝' Related Articles
more




Comments